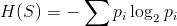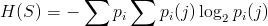Tveir þættir virðast aðallega hafa áhrif á hversu erfitt er að búa til krossgátu á tilteknu máli, annars vegar hversu mörg orð eru fyrir hendi í málinu til að setja í gátuna og hins vegar hversu auðvelt er að giska á orð út frá nokkrum stöfum og raða þeim saman í gátu. Fyrri þátturinn er reyndar ekki jafn takmarkandi og hann virðist við fyrstu sýn. Þar sem það á að vera hægt að leysa krossgátur þá verður að smíða þær með orðum sem eru í einhverri notkun. Bæði í ensku og íslensku eru til fleiri hundruð þúsund orð og því hefur seinni þátturinn líklega meiri áhrif á erfiðleika við krossgátusmíðar en sá fyrri. Til að reyna að mæla þennan seinni þátt notast vísindamenn við svonefnda óreiðu.
Í málvísindum er hugtakið óreiða notað um það hversu fyrirsjáanlegt tungumálið er. Óreiðu tungumáls er annars vegar hægt að reikna út frá orðum og hins vegar út frá stöfum. Þegar óreiða orða er reiknuð er verið að athuga hversu auðvelt er að giska á heilt orð út frá hluta þess. Óreiðan fer þá mikið eftir eðli textans og er mjög mismunandi eftir efni hans, af því að textar um mismunandi hluti geta notað mjög mismunandi orðaforða. Óreiða stafa í orðum er hins vegar minna háð textasafninu.
Claude E. Shannon (1916 - 2001).
Þekktustu mælingar á óreiðu stafa voru gerðar af Shannon árið 1950, en tveimur árum áður hafði hann skilgreint óreiðu í tungumálum og hvernig ætti að reikna hana. Hann skilgreindi óreiðu, sem er táknuð með bókstafnum H, sem fjölda bita sem þarf til að tákna stafi í tungumáli. Því hærri tala sem H er, því óreglulegra er málið og erfiðara að spá fyrir um hvað kemur næst.
Auðvelt er að reikna út óreiðu fyrir einstöfunga, en einstöfungar eru stakir bókstafir, svo sem a, b og d. Þá er í raun verið að reikna út hversu auðvelt sé að giska á næsta staf í orði ef engar upplýsingar eru um þá stafi sem koma á undan honum. Líkurnar á hverjum bókstaf er tíðni bókstafsins í textanum sem reiknað er út frá og einstöfungar eru óháðir öðrum bókstöfum. Óreiðu einstöfunga er hægt að reikna út með formúlunni:
þar sem pi eru líkurnar á því að stafur númer i komi fyrir.
Óreiða er oft einnig reiknuð út fyrir tvístöfunga og þrístöfunga, en tvístöfungar eru tveir stafir saman, til dæmis aa, gh og tr, og eins eru þrístöfungar þrír stafir saman. Þegar óreiða er reiknuð út fyrir tvístöfunga þarf að reikna út hversu líklegt sé að við giskum á eftirfarandi staf ef fyrsti stafur er þekktur. Ef við vitum að fyrsti stafur í tvístöfungi er h, þá vitum að mun líklegra er í íslensku að næsti stafur sé a fremur en ð því að tvístöfungurinn ha er algengari en hð. Fyrir tvístöfunga gildir aðeins flóknari formúla:
þar sem pi er eins og áður, en pi(j) eru líkurnar á því að stafur númer j komi á eftir staf númer i.
Við útreikninga á þrístöfungum og fjórstöfungum þarf mikið magn texta þar sem mögulegar samsetningar bókstafa margfaldast í hvert skipti sem við bætum við staf. Í 32 stafa stafrófi eru möguleikar einstöfunga aðeins 32, mögulegir tvístöfungar eru 32 x 32 = 1.024, til eru 32 x 32 x 32 = 32.768 þrístöfungar og mögulegir fjórstöfungar eru 32 x 32 x 32 x 32 = 1.048.576.
Nafnið óreiða kemur frá svipuðu hugtaki í varmafræði.
Orðasafn þarf að vera mjög stórt til að innihalda nógu marga fjórstöfunga til að gefa rétt hlutfall þeirra. Því er ekki álitlegt að reikna út óreiðu fyrir fjórstöfunga. Í raun er illmögulegt að reikna út tölfræðilega óreiðu fyrir langa stöfunga og því er takmarkað notagildi af aðferðinni. Þar að auki er raunveruleg óreiða stafa mun lægri en tölfræðilegir útreikningar benda til. Shannon reiknaði út að í 27 stafa stafrófi (26 stafir enska stafrófsins auk bils) væri óreiða 4.03 fyrir einstöfunga og 3.32 fyrir tvístöfunga, en þegar hann lét fólk giska á stafina í textanum fékk hann út óreiðuna 1.78.
Til eru bráðabirgðaútreikningar fyrir óreiðu í íslensku. Þeir voru fengnir þannig að tölur úr Íslenskri orðtíðnibók voru slegnar inn í töflureikni og reiknað úr þeim. Vandi skapast af því að íslensk orðtíðni tekur líka erlenda bókstafi svo sem c, q, w, z. Í þessum útreikningum var erlendum bókstöfum sleppt og því kemur inn ákveðin óvissa vegna tvístöfunga í erlendum orðum sem eru með íslenska stafi, eins og til dæmis tvístöfungar í nafninu John, það er jo, oh og hn, en við getum ekki þekkt þá frá sömu tvístöfungum úr íslenskum orðum. Þar sem orðasafnið er svo stórt verður þessi skekkja þó líklega óveruleg.
Þegar við berum tölurnar sama við útreikninga Shannons fyrir 26 stafa stafróf, en það er án bils eins og útreikningarnir fyrir íslensku stafina, kemur í ljós að þótt íslenskan sé óreglulegri þegar einn stafur er skoðaður út frá tíðni, þá er hún strax orðin reglulegri en enskan þegar tvístöfungar eru skoðaðir. Það bendir til þess að íslensk orð séu reglulegri en ensk. Þetta þýðir meðal annars að þjöppun á íslenskum texta í tölvum ætti að vera meiri en í ensku og einnig að erfiðara hljóti að vera semja krossgátur á íslensku en ensku, af því að bæði eru orðin fyrirsjáanlegri og það er einnig erfiðara að finna orð sem passa. Þó skal hafa þann fyrirvara á að ekki er hér um birtar niðurstöður að ræða og þessar tölur verða því að skoðast sem bráðabirgðaniðurstöður.
Tengt efni á Vísindavefnum:
Ásdís Bergþórsdóttir. „Hvort er erfiðara að gera krossgátur á íslensku en ensku?“ Vísindavefurinn, 26. júní 2009. Sótt 19. apríl 2024. http://visindavefur.is/svar.php?id=53021.
Ásdís Bergþórsdóttir. (2009, 26. júní). Hvort er erfiðara að gera krossgátur á íslensku en ensku? Vísindavefurinn. Sótt af http://visindavefur.is/svar.php?id=53021
Ásdís Bergþórsdóttir. „Hvort er erfiðara að gera krossgátur á íslensku en ensku?“ Vísindavefurinn. 26. jún. 2009. Vefsíða. 19. apr. 2024. <http://visindavefur.is/svar.php?id=53021>.
Hér getur þú sent okkur nýjar spurningar um vísindaleg efni.
Hafðu spurninguna stutta og hnitmiðaða og sendu aðeins eina í einu. Einlægar og vandaðar spurningar
um mikilvæg efni eru líklegastar til að kalla fram vönduð og greið svör. Ekki er víst að tími vinnist til að
svara öllum spurningum.
Persónulegar upplýsingar um spyrjendur eru eingöngu notaðar í starfsemi vefsins, til dæmis til að
svör verði við hæfi spyrjenda. Spurningum er ekki sinnt ef spyrjandi villir á sér heimildir eða segir ekki
nægileg deili á sér.
Spurningum sem eru ekki á verksviði vefsins er eytt.
Að öðru leyti er hægt að spyrja Vísindavefinn um allt milli himins og jarðar!